What Is Trino And Why Is It Great At Processing Big Data

Photo by Pawel Czerwinski on Unsplash
Big data is touted as the solution to many problems. However, the truth is, big data has caused a lot of big problems.
Yes, big data can provide more context and provide insights we have never had before. It also makes queries slow, data expensive to manage, requires a lot of expensive specialists to process it, and just continues to grow.
Overall, data, especially big data, has forced companies to develop better data management tools to ensure data scientists and analysts can work with all their data.
One of these companies was Facebook who decided they needed to develop a new engine to process all of their petabytes effectively. This tool was called Presto which recently broke off into another project called Trino.
In this article, we outline what Trino is, why people use it and some of the challenges people face when deploying it.
What Is Trino
Let’s be clear. Trino is not a database. This is a misconception. Just because you utilize Trino to run SQL against data, doesn’t mean it’s a database.
Instead, Trino is a SQL engine. More specifically, Trino is an open-source distributed SQL query engine for adhoc and batch ETL queries against multiple types of data sources. Not to mention it can manage a whole host of both standard and semi-structured data types like JSON, Arrays, and Maps.
Another important point to discuss about Trino is the history of Presto. In 2012 Martin Traverso, David Phillips, Dain Sundstrom and Eric Hwang were working at Facebook and developed Presto to replace Apache Hive to better process the hundreds of petabytes Facebook was trying to analyze.
Due to the creators desire to keep the project open and community based they open sourced it in November 2013.
But due to Facebook wanting to have tighter control over the project there was an eventual split.
The original creators of Presto decided that they wanted to keep Presto open-source and in turn pursued building the Presto Open Source Community full-time. They did this under the new name PrestoSQL.
Facebook decided to build a competing community using The Linux Foundation®. As a first action, Facebook applied for a trademark on Presto®. This eventually led to litigation and other challenges that forced the original group who developed Presto to rebrand.

Starting in December 2020 PrestoSQL was rebranded as Trino. This has been a little confusing but now Trino supports a lot of end-users and has a large base of developers that commit to it regularly.
How does Trino work?
Trino is a distributed system that utilizes an architecture similar to massively parallel processing (MPP) databases. Like many other big data engines there is a form of a coordinator node that then manages multiple worker nodes to process all the work that needs to be done.
An analyst or general user would run their SQL which gets pushed to the coordinator. In turn the coordinator then parses, plans, and schedules a distributed query. It supports standard ANSI SQL as well as allows users to run more complex transformations like JSON and MAP transformations and parsing.
Why People Use Trino
Trino, being a Presto spin-off, has a lot of benefits that came from its development by a large data company that needs to easily query across multiple data sources without spending too much time processing ETLs. In addition, it was developed to scale on cloud-like infrastructure. Although, most of Facebook’s infrastructure is based on its internal cloud. But let’s dig into why people are using Trino.
Agnostic Data Source Connections
There are plenty of options when it comes to how you can query your data. There are tools like Athena, Hive and Apache Drill.
So why use Trino to run SQL?
Trino provides many benefits for developers. For example, the biggest advantage of Trino is that it is just a SQL engine. Meaning it agnostically sits on top of various data sources like MySQL, HDFS, and SQL Server.
So if you want to run a query across these different data sources, you can.
This is a powerful feature that eliminates the need for users to understand connections and SQL dialects of underlying systems.
Cloud-focused
Presto’s fundamental design of running storage and computing separately makes it extremely convenient to operate in cloud environments. Since the Presto cluster doesn’t store any data, it can be auto-scaled depending on the load without causing any data loss.
Use Cases For Trino
Adhoc queries And Reporting – Trino allows end-users to use SQL to run ad hoc queries where your data resides. More importantly, you can create queries and data sets for reporting and adhoc needs.
Data Lake Analytics – One of many of the common use cases for Trino is being able to directly query data on a data lake without the need for transformation. You can query data that is structured or semi-structured in various sources. This means you can create operational dashboards without massive transformations.
Batch ETLs – Trino is a great engine to run your ETL batch queries. That’s because it can process large volumes of data quickly as well as bring in data from multiple sources without always needing to extract data from sources such as MySQL.
Challenges For Trino Users
At this point, you might be assuming that everyone should use Trino. But it’s not that simple. Using Trino requires a pretty large amount of set-up for one. However, there are also a few other issues you might deal with upon set-up.
Federated Queries Can Be Slow
The one downside of federated queries is that there can be some trade-offs in speed. This can be caused by a lack of meta-data stored and managed by Trino to better run queries. In addition, Presto was initially developed at Facebook that essentially has their own cloud. For them to expand it and grow it as they need increased speed isn’t a huge problem. However, for other organizations, in order to get the same level of performance they might need to spend a lot more money to add more machines to their clusters. This can become very expensive. All to manage unindexed data.
One such example is Varada. Varada indexes data in Trino in such a way that reduces the time the CPU is used for data scanning (via indexes) and frees the cpu up for other tasks like fetching the data extremely fast or dealing with concurrency. thus allows SQL users to run various queries, whether across dimensions, facts as well as other types of joins and datalake analyticss, on indexed data as federated data sources. SQL aggregations and grouping is accelerated using nanoblock indexes as well, resulting in highly effective SQL analytics.
Configuration And Set-Up
Setting up Trino isn’t straightforward. Especially when it comes to optimizing performance and management. In turn, many system admins and IT teams will need teams to both set up and manage their instances of Trino.
One great example of this is an AWS article titled “Top 9 Performance Tuning Tips For PrestoDB“.
Lack Of Enterprise Features
One of the largest challenges faced by companies utilizing Trino is that out of the box, there aren’t a lot of features geared towards enterprise solutions. That is to say, features that revolve around security, access control, and even expanded data source connectivity are limited. Many solutions are trying to be better provided in this area.
A great example of this is Starburst Data.
Starburst Enterprise has several features that help improve the Trino’s lacking security features. For example, Starburst makes it easy for your team to set up access control.
The access control systems all follow role-based access control mechanisms with users, groups, roles, privileges and objects.
This is demonstrated in the image below.
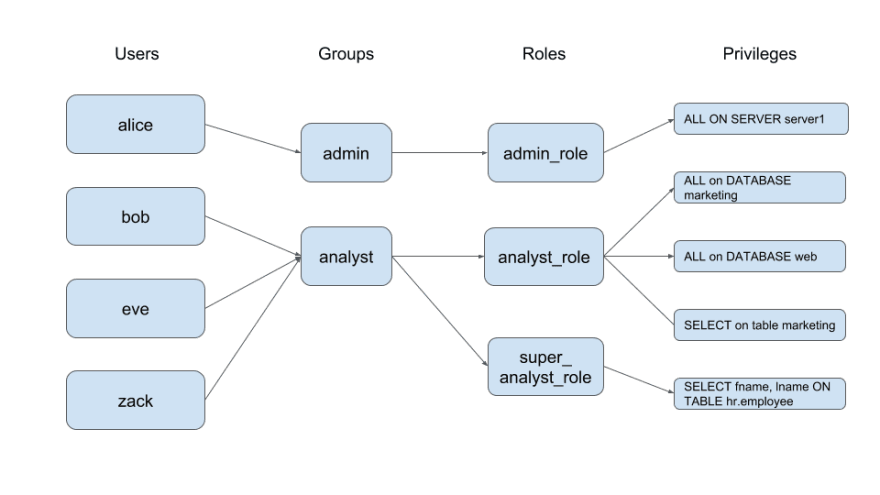
This makes it easy for your security teams and data warehouse administrators to manage who has access to what data.
Starburst also offers other helpful security features such as auditing and encryption.
This enables companies to implement a centralized security framework without having to code their own modules for Trino.
Conclusion
Big data will continue to be a big problem for companies that don’t start looking for tools like Trino to help them manage all their data. Trino’s ability to be an agnostic SQL engine that can query large data sets across multiple data sources is a great option for many of these companies. But as discussed, Trino is far from perfect. It isn’t fully optimized in a way for enterprise companies to take advantage of its full abilities. In addition, due to Trino’s brute force approach to speed, it sometimes comes at a cost. It becomes very expensive to get the beneficial speed without indexing.
This is where many new solutions are coming into the fold to make Trino more approachable. In the end, big data can be maintained and managed, you just need the right tools to help set yourself up for success.
If you enjoyed this article, then check out these videos and articles below.
Data Engineer Vs Analytics Engineer Vs Analyst
How To Find The Best Deals On Time With R And Mage
Why Migrate To The Modern Data Stack And Where To Start
5 Great Data Engineering Tools For 2021 — My Favorite Data Engineering Tools
4 SQL Tips For Data Scientists
What Are The Benefits Of Cloud Data Warehousing And Why You Should Migrate