Apache Druid’s Architecture – How Druid Processes Data In Real Time At Scale
 Recently, I wrote an article diving into what Druid is and which companies are using it. Now I wanted to do a deeper dive into Apache Druid’s architecture.
Recently, I wrote an article diving into what Druid is and which companies are using it. Now I wanted to do a deeper dive into Apache Druid’s architecture.
Apache Druid has several unique features that allow it to be used as a real-time OLAP. Everything from its various nodes and processes that each have unique functionality that let it scale to the fact that the data is indexed to be pulled quickly and efficiently.
So what makes Druid’s architecture unique and tuned for dealing with real-time analytics?
Overview of Druid’s Architecture
Druid’s architecture is designed to balance the demands of real-time data ingestion, fast query performance, and scalability. It achieves this balance through a combination of several core components:
- Broker Process: Query routing nodes that parse queries, distribute them to the relevant data nodes, and aggregate the results.
- Historical Process: This process stores and serves segments of immutable, historical data.
- Middle Manager Process: This process is responsible for stream ingestion and handoff, managing the ingestion tasks, and indexing data in real-time. It creates and manages a Peon process for each incoming stream.
- Coordinator Process: This process manages cluster metadata and oversees the distribution of segments across Historical Processes.
- Overlord Process: The orchestration layer that manages locks and tasks.
- Router process – This process is used to route queries to different Broker processes, based on Rules set up to manage workload optimization, such as creating “lanes” for higher- and lower-priority queries.
Data Flow in Druid: From Ingestion to Query Processing
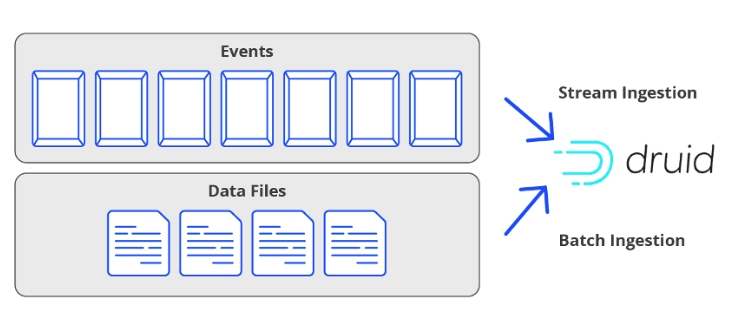
The data flow in Druid begins with ingestion, where data can be streamed in real-time through Apache Kafka, Amazon Kinesis, or batch-loaded from a file system. During ingestion, data is partitioned and indexed. Then the data is stored in segments, a fundamental unit of storage in Druid(which we will talk more about in the next section).
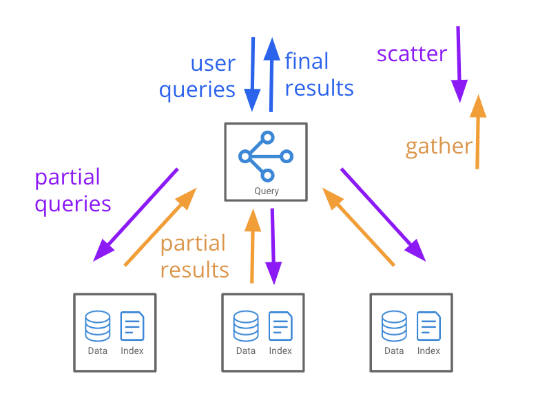
Once ingested, data is available for querying. Queries are issued to the Broker processes, which then scatter the queries to Historical processes for historical data and to Peons for real-time data. The results from these processes are then gathered, merged, and returned to the user by the Broker.
That was a lot, so let’s dive deeper into each of the unique components of Apache Druid’s architecture
Data Storage
Earlier, I referenced segments and indexes. I wanted to avoid being hand-wavey and just assume it was clear what was happening in these specific components. So now let’s dig into how Apache Druid stores data.
Segments: The Basic Unit of Data Storage in Druid
In Apache Druid, the fundamental unit of data storage is the “segment.” A segment is a data block that contains a collection of columns, a piece of a table with a structure optimized for high-speed data retrieval and aggregation. Segments are immutable once created, allowing Druid to efficiently cache and distribute them across the cluster for parallel processing.
Deep Storage
Deep storage in Druid refers to the durable, long-term storage of data segments. Druid is designed to be agnostic to the choice of deep storage and supports various options, such as the Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage, and Microsoft Azure Storage. The role of deep storage is to provide a reliable repository from which segments can be retrieved and loaded into Historical processes for query processing.
Indexing and Partitioning of Data
To optimize storage and retrieval, Druid segments are both indexed and partitioned. The indexing within a segment includes inverted indexes to speed up queries that filter on specific column values. Partitioning, on the other hand, can be based on time intervals or other segment-level characteristics, helping distribute data evenly across the cluster and minimizing query latencies by narrowing the search space.
Data Ingestion
Batch Ingestion vs. Real-Time Ingestion
Druid supports two primary methods of data ingestion: batch and real-time. Batch ingestion is suitable for large volumes of historical data that can be ingested and indexed in bulk, typically from static files. Real-time ingestion, in contrast, is used for streaming data, allowing for the immediate availability of data for querying.
Ingestion Methods
Druid offers several ingestion methods to accommodate different data pipelines:
- Kafka: For streaming data ingestion directly from Apache Kafka topics or Kafka-compatible systems like Confluent and Red Panda.
- Hadoop: Leveraging the Hadoop ecosystem for batch processing, particularly useful for large datasets.
- Native Batch: Direct ingestion from files without the need for external dependencies like Hadoop. Support standard formats like CSV, Parquet, ORC, Avro, Protobuf, and Iceberg.
- AWS Kinesis: AWS Kinesis is a managed platform that provides real-time data streaming.
Query Execution
Druid’s Query Language and SQL Compatibility
Druid’s native query language is JSON over HTTP, allowing for highly flexible and granular query constructs. However, understanding the need for standardization and ease of use, Druid also provides SQL compatibility, enabling users to query data using familiar SQL syntax while leveraging Druid’s performance optimizations.
Caching and Query Optimization Strategies
Druid employs several caching and optimization strategies to enhance query performance:
- Result-level Caching: Caches the final results of queries on the Broker processes, allowing for rapid data retrieval for repeated queries.
- Segment-level Caching: Historical processes cache data segments, reducing the need to repeatedly read from deep storage.
- Query Optimization: Druid automatically optimizes queries by rewriting them or by choosing the most efficient execution path, considering factors like data distribution and the current state of the cluster.
Through its sophisticated architecture and comprehensive feature set, Druid is engineered to meet the challenges of modern data analytics, providing fast, scalable, and reliable data storage, ingestion, and query capabilities.
Scalability and Fault Tolerance
Apache Druid’s architecture is inherently distributed, designed to scale horizontally by adding more resources to the cluster. This scalability is a cornerstone of Druid’s ability to handle massive datasets and concurrent queries without compromising performance.
Distributed Architecture and Scalability
Druid’s ability to scale comes from its distributed components, each responsible for specific tasks such as data ingestion, storage, and query processing. As the data volume or query load increases, additional processes can be added to the cluster to distribute the workload more evenly. This ensures that the system can grow with the data, maintaining high performance and responsiveness.
Replication and Fault Tolerance Mechanisms
To ensure high availability, Druid employs replication strategies that duplicate data segments across multiple Historical processes. This redundancy means that if a process fails, the system can automatically reroute queries to replicas of the lost segments on other processes. Druid’s design also includes mechanisms for automated recovery and the rebalancing of data, further enhancing its fault tolerance.
Conclusion
I can see its value for Business Intelligence teams wanting to get quick insights on a variety of data stored in a variety of places. I love the nice GUI and the straightforward way to load data sources, the SQL workbench is also very nice.
Apache Druid’s architecture makes it well-suited to handle real-time analytics, and in most cases, real-time analytics applications. That’s because when it’s set up properly, Apache Druid can scale both in terms of storage computing. Additionally, as we discussed, it has the functionality for caching, making Druid well-suited for the use cases we discussed in the prior article.
If you’d like to read more about data engineering and data science, check out the articles below!
Why Is Data Modeling So Challenging – How To Data Model For Analytics
OLTP vs OLAP: Key Differences, Examples, and Use Cases for Beginners
How to build a data pipeline using Delta Lake
Intro To Databricks – What Is Databricks